Kubernetes Controllers - A new hope
Today I’m going to introduce you an idea Markus Thömmes and I had to package, deploy and operate Kubernetes controllers in a modern and efficient way that may have a fundamental impact on the Kubernetes ecosystem.
Introduction
Kubernetes is the standard de-facto container orchestration engine of these days. As every orchestrator of “something” (bare metal machines, VMs, containers, etc), one day you need to expand the available abstractions the system provides to you. For Kubernetes, that day came around 3 years ago where they introduced the concept of Custom Resource.
To put it simply, everything you create/read/update/delete in Kubernetes is an API Resource. A CRD (Custom Resource Definition) defines a new resource you can create/read/update/delete in your cluster, which is not included in the built-in ones, while a CR (Custom Resource) is an instance of the CRD. For example, a Pod is a Kubernetes resource from the core API group, a Broker is a CRD introduced when you install Knative Eventing on your Kubernetes cluster.
With a definition of a new resource, you need to implement the business logic to orchestrate it, that is to handle create/read/update/delete operations on the resource. For example, you might want spawn a new etcd pod every time somebody creates a new EtcdCluster CR. In order to do that, you need to implement a Kubernetes controller: an application that listens for events on one or more API resources and reacts performing some operations on the cluster.
Since the introduction of CRDs, we’ve seen a huge expansion of extensions to Kubernetes APIs. Kubernetes vendors are using CRDs to provide distributions well integrated with their underlying systems, software vendors are developing controllers to simplify the operations on Kubernetes environment (for example Strimzi to deploy Kafka on Kubernetes), new projects are born to provide middleware and tooling to develop applications on top of Kubernetes (Knative to create serverless applications). Marketing around Kubernetes even forged a new name for the last use case: Kubernetes native applications, aka applications where the API-surface relies on the CRDs. In OpenShift there is even a system, based on a bunch of CRDs, to install other CRDs with their respective controllers.
Although there is a distinction between controllers and operators, for the sake of simplicity in this post I’m going to always refer to controller as the entity that implements the business logic of a CRD.
This concept works pretty well for Kubernetes, although there are still some open questions about the controller itself. In this post I’m going to introduce you a solution Markus Thömmes and I designed that may revolutionize how we package, deploy and operate Kubernetes controllers.
Kubernetes controllers today
Today a Kubernetes controller consists of more or less:
- A main loop that does long polling to Kubernetes to watch one or more resources
- On every event, a function called reconciler is invoked to align the cluster state to the desired state. For example: if the desired state expects a Pod to be running, but for some reason there isn’t, then the reconciler creates it.
- The reconciler optionally set the status of the CR, like Ready, SomeError, …
After we implement the controller, we need to configure and apply the Custom Resource Definition and we need to setup a Service Account, that is an account to connect to our Kubernetes cluster in order to perform the operations the reconciler does.
During the years a lot of tooling was created, mostly in Golang, to implement these controllers, depending on the user needs. To mention some of them:
Other projects, like Knative, opt for creating and maintaining their own tooling to implement controllers.
These tools usually provide:
- A library to improve the event handling logic: “smart” events queue that deduplicate and filter events for example
- A code generator component that, starting from the CRD defined in the code, scaffolds the controller code and generates the client code to interact with the CRD
In essence, all of these tools work the same though in that ultimately they will generate a binary containing the controller. Each binary can in theory contain a number of controllers, for example Knative’s framework actively encourages that with a main interface to start multiple controllers at same time. Crucially though, collapsing more than one controller into one binary and thus one process in the Kubernetes cluster needs to happen at compile time.
With the systems commonly used, we’ll get at least one process (aka Pod) per project that extends Kubernetes (i.e. at least one Pod for Knative CRDs, at least one Pod for Strimzi CRDs etc.). Each of those processes will be mostly idle for most of their lifetime, but they will steadily consume resources nonetheless.
In short: We’re flooding our Kubernetes clusters with applications that suck resources and remain in idle for most of their time!
Extending Kubernetes APIs in process
The idea behind our solution is to create a runtime plugin system where every plugin is a Kubernetes controller.

This plugin system should have certain traits:
- Plugins should be well isolated between each other so no single plugin’s failure/bad behaviour can cause trouble in other plugins
- The host should be able to control and restrict what the plugin can do
- Users should be able to develop plugins with different languages
- The host should be able to load and unload plugins at runtime, without restarting the system
This plugin system can be seen as a mega controller. It can run as its own process, or it could even be merged with the kube-controller-manager, which is the process with all the controllers that manage the Kubernetes built-in resources:

Isolated, multi-language, lightweight plugin system? That sounds hard…
The requirements of the plugin system are not trivial, but lucky for us WebAssembly (Wasm) comes in rescue!
Wasm is an instruction set, targetable from every programming language, that runs in an isolated Virtual Machine.
From webassembly.org: “WebAssembly (abbreviated Wasm) is a binary instruction format for a stack-based virtual machine. Wasm is designed as a portable compilation target for programming languages, enabling deployment on the web for client and server applications”.
That sounds like the perfect fit for our idea:
- Because it’s isolated by default, we define all the possible interactions between the plugins (controllers) and the host, piece by piece
- Because it runs in a sandboxed virtual machine, it can easily isolate catastrophic failures and guarantee safe access to specific memory regions
- Because it’s a general purpose instruction set, more similar to an ISA of a modern CPU other than the JVM bytecode, most languages can target it (GC-enabled, dynamic/static typed, …).
A list of supported languages is available here and here. Wasm is flexible enough that it can be executed with ahead of time (AOT) compilation or with a just in time (JIT) interpreter.
Although WebAssembly sounds like a web or browser technology, in the last years several people are experimenting with this technology outside the browser. Most notably, CloudFlare Function as a Service offering called Workers uses Wasm to run C/Rust code using Google’s V8 isolations.
With WebAssembly, our plugin system looks like:
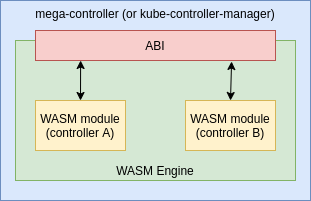
When we develop a controller, the compiled artifact is a binary Wasm module. A Wasm engine loads this module, eventually compiles it in AOT cases, and executes it.
At this point, we need to define the interaction semantics between the host and the plugins. In order to do that, we define the ABI (Application Binary Interface) of our plugin system: the functions the host imports in our plugin and the functions the plugin exports in our host.
Show me your ABI!
First of all, an example of a Wasm ABI. This is the Rust code for a Wasm module:
1 |
|
This Wasm module exports the function foo, which means that, after the module has been loaded, the engine can invoke foo to execute it. On the other side, when we load the module in the engine, we must link some logic to the function println in order to run it, otherwise we’ll get a link error.
We can get all imports and exports of a module using a tool called wasm-nm.
1 | wasm-nm module.wasm -i #Get the imports |
This is the most important design choice of the project: the ABI influences the capabilities the host needs to implement, the portability of existing controllers, the APIs on the plugin side and so on. When we design the ABI we also need to take the differences of the programming languages into account: as an example, some may require additional interfaces to the host to run asynchronous code. The async schedulers in Rust and the goroutine scheduler in Golang both require a syscall to sched_yield to yield a thread execution in this example.
WASI
Lucky for us, part of the job that includes the low-level primitives is covered by a work in progress spec called WASI (WebAssembly System Interface). Their goal is to provide a reduced set of POSIX-like APIs: read/write files, get system clock, get environment variables and program arguments, read/write a socket and so on. Although, as they state in their rationale document, it’s not goal of WASI to include primitives to open sockets/files, this is left to the users. From their docs:
One of WebAssembly’s unique attributes is the ability to run sandboxed without relying on OS process boundaries. Requiring a 1-to-1 correspondence between wasm instances and heavyweight OS processes would take away this key advantage for many use cases. Fork/exec are the obvious example of an API that’s difficult to implement well if you don’t have POSIX-style processes, but a lot of other things in POSIX are tied to processes too. So it isn’t a simple matter to take POSIX, or even a simple subset of it, to WebAssembly.
A socket is a process wide resource. This means that if module A opens a TCP socket, module B might have access to it if we don’t implement proper security countermeasures.
Designing the ABI
Given our knowledge and studies of the current state of art for Wasm ABIs, we found out there are 3 possible non mutually exclusive approaches to the ABI design:
- High level ABI: Expose the Kubernetes client functionalities
- Medium level ABI: Proxy the HTTP client functionalities (send HTTP request, receive HTTP response)
- Low level ABI: Proxy the syscalls (
epoll,read,write,bind, …)
We think that a good solution should mix all these 3 “levels”. Some low-level APIs are always necessary for basic things like logging, getting configuration from environment, setting timeouts and so on.
Proxying HTTP can be useful to invoke services outside Kubernetes (e.g. to trigger a cloud vendor API to enable a service).
Exposing the Kubernetes client APIs unlocks a great potential to optimize the controllers beyond the optimized resource usage indicated above. Most prominently: the so called informer infrastructure can be shared between all the controllers. An informer is the part of a controller that listens for events on given resources. It builds up local caches that effectively reflect the state of said resources in-memory.
In our case, the host would setup these informers and watches just once per resource. If two controllers want to watch ConfigMaps for example, the host would only need to setup one watch and keep one cache, reducing the amount of network traffic due to event delivery and memory consumption due to caching drastically. That effect becomes more and more pronounced as more extensions are being added.
Following the above approach, the host has always the full control of process resources (open files, open sockets, etc), we allow the modules to perform only certain operations and, most important, we open up for huge optimizations.
Our prototype
Markus and I built a prototype of the host and of the 2 controllers, a simple pod spawner and the Memcached example from operator-sdk. You can find all the code here: https://github.com/slinkydeveloper/extending-kubernetes-api-in-process-poc
The host is implemented in Rust and Wasmer, a popular Wasm engine supporting different compilation backends and with several language bindings. We implemented the controllers with Rust using a hacked version of kube-rs client.
The host logic is pretty simple: when it starts, it reads the contents of the specified dir, looking for .yaml containing the module manifests. An example manifest:
1 | name: memcached |
name is the operator name and abi is the abi the host should use to interact with the module. This allows to support different ABIs at the same time, mainly to overcome the differences between the programming languages and to support old modules running on new host versions.
Then, for each module, it compiles and runs it in a separate thread invoking the exported run function. The module, through the custom ABI we designed, can interact with Kubernetes to start watching resources and react to the events.
The prototype contains several simplifications that we can overcome easily (like watching the modules directory more than loading all the modules once), while others require more engineering as discussed later in this post.
The ABI
In order to create a running prototype, we ended up with a pretty simple ABI that mixes the low level WASI syscalls with a medium level HTTP client proxy functionality:
1 | wasm-nm memcached.wasm -i |
The exports are run to start the controller and allocate to allocate memory on the module. The implementer of the controller just implements the resources watch loop inside the run function.
In Wasm the module cannot access to the host memory, but the host can access to the module memory and copy bytes inside it. Because the Wasm module might have a memory allocator, a GC or any other mechanism to manage memory, the module should export a function that allocates memory to let the host copy bytes back to the module.
request is the function to perform a blocking and buffered HTTP request, while all the other imports come from WASI. The user interacts with our hacked version of the Kubernetes client, which under the hood invokes request to perform HTTP requests using reqwest crate. All our APIs are blocking because currently there is no out of the box async/await support in Wasm modules, I’ll cover this limitation later.
The request flow should give you an idea of what it takes to implement an ABI:
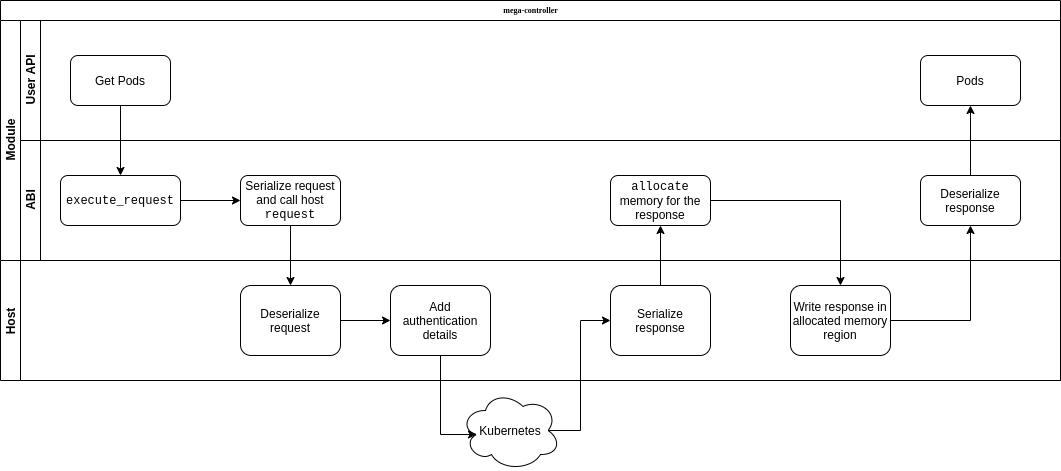
The host takes care of handling the authentication, in order to avoid the controller having to have access to files at all.
The controller
An example code for the controller looks like:
1 | let client = Client::default(); |
You can look at the full controller code for the above sample here. The user potentially doesn’t know that their code is run inside an isolation. Everything is hidden behind the usual Kubernetes client APIs. In other words: The programming model does not change.
Next steps
There are some things we still haven’t tested, but that we’re willing to do in order to give us a clear idea of how to grow this idea:
- Re-design the ABI to support unbuffered & asynchronous HTTP requests. This requires several additions to both the Wasm engine and the host code, most notably the engine should have the ability to yield the execution and the module should have an async executor to execute async operations.
- The proposed ABI mixes medium level and low level. We want to try to implement a high level function in our ABI for watching Kubernetes resources, in order to register a single watch for all the controllers.
- The actual ABI doesn’t have error management at all, but that shouldn’t be hard to implement: the serialized ABI data structures might be enums with error as one of the variants, so then the error is propagated back to the user as a
Result.
Wait, where is Golang?
Our dream is to port existing controllers to this approach. Most of Kubernetes world today lives in Golang, but up until this point I didn’t talk at all about Golang. Why?
The reason is that we found some critical issues within the Wasm/Golang support, among the others Golang assumes that the Wasm engine runs inside a JS VM using wasm_exec.js. In order to understand the impact of this choice, let me go through the Golang standard library implementation in Wasm.
Today in Golang, when you compile to Wasm, all the standard library I/O operations go through the syscall/js module, which invokes a predefined set of imports in your module. From the doc: Package js gives access to the WebAssembly host environment when using the js/wasm architecture. Its API is based on JavaScript semantics.:
Global()allows you to get theglobalobjectInvoke()allows you to use ajs.Valueas a function and invoke it
Now let’s analyze how the net/http client implementation on Wasm: When the user invokes RoundTrip, the request is transformed in a Javascript object, then using the syscall Global and Call the javascript global function fetch is invoked and finally, on the returned promise, the two callbacks are set to handle response and error.
The problem with this approach, although it works well in the browsers, is that the engine needs to implement all these JS functions used by Golang standard library. If we’re not using a Javascript based runtime, we need to reimplement this. Further, it requires us to secure access to the global object fields, in order to retain the isolation properties.
To make things even worse, at the moment there is no way to define imports and exports within the module, so we cannot define and evolve an ABI that fits our needs. The only workable solution with the existing tools consists in define “fake” Javascript functions on the host side for the imports and setting “fake” fields on the “fake” global object for the exports, but this approach makes the code far more complex and convoluted, both on host and Wasm module side.
While the official Golang distribution doesn’t support definining imports and exports, TinyGo supports it
Markus managed to run the Memcached operator example of operator-sdk, using NodeJS as a host, hacking some polyfills to match the expectations of wasm_exec.js. The final module ABI is:
1 | wasm-nm test.wasm -i |
I was initially puzzled by the resume and getsp exports of the Wasm module, but then digging in the wasm_exec.js codebase their existence was justified: using resume and getsp the host can yield the execution of the module, perform some async operations, and then resume the execution of the code. That’s the very same solution I would love to implement in our Rust ABI prototype and, as far as I know, WASI is looking for a generalized solution to support async runtimes inside the modules.
This experiment proves that Golang/Wasm support can definitely work and we think that, without the constraints of syscall/js and with the ability to define our ABI, we could port all the existing controllers to compile in Wasm isolated modules.
Some interesting issues to follow about Golang and Wasm related to this discussion:
There is still a long road ahead
Our long-term goal is to improve the Kubernetes ecosystem, creating a production ready plugin system with low footprint. We encourage the Kubernetes community to give us feedback on our findings and our prototype, so we can work together on shaping the future of Kubernetes controllers!
Check out the second part of this blog post series: Kubernetes controllers: The Empire Strikes Back